Langfuse Update — September 2023
Model-based evals, datasets, core improvements (query engine, complex filters, exports, sharing) and new integrations (Flowise, Langflow, LiteLLM)
Hi everyone 👋, here’s a quick overview of all the most notable new features we shipped in September:
-
Model-based evaluations via Python SDK
-
Datasets (beta) to collect sets of inputs and expected outputs in Langfuse to evaluate your LLM app
-
In-app analytics powered by new query engine
-
New integrations with Flowise, Langflow and LiteLLM
-
Improvements
- Complex filters for all tables
- Share traces via public link
- Export generations as CSV, JSON or JSONL (e.g. for fine-tuning)
… and many small improvements and bug fixes.
The details 👇
🚦 Model-based evaluations via Python SDK
We’ve added an example implementation on how to run model-based evaluations on production data in Langfuse using the Python SDK.
The new get_generations method allows you to fetch all generations based on a filter (e.g. name). You can then run your eval function on each generation and add the scores to Langfuse for exploration.
With this, you can run your favorite eval library (e.g. OpenAI evals, Langkit, Langchain) on all generations in Langfuse.
from langfuse import Langfuse
langfuse = Langfuse(LF_PUBLIC_KEY, LF_SECRET_KEY)
generations = langfuse.get_generations(name="my_generation_name").data
for generation in generations:
# import function from an eval library, see docs for details
eval = hallucination_eval(
generation.prompt,
generation.completion
)
langfuse.score(
name="hallucination",
traceId=generation.trace_id,
observationId=generation.id,
value=eval["score"],
comment=eval['reasoning']
)→ Docs
🗂️ Datasets (beta)
Systematically test new iterations of your LLM app with datasets.
Datasets are collections of inputs and expected outputs that you can manage in Langfuse. Upload an existing dataset or create one based on production data (e.g. when discovering new edge cases).
When combined with automated evals, Datasets in Langfuse make it easy to systematically evaluate new iterations of your LLM app.
Overview of dataset runs on a demo dataset
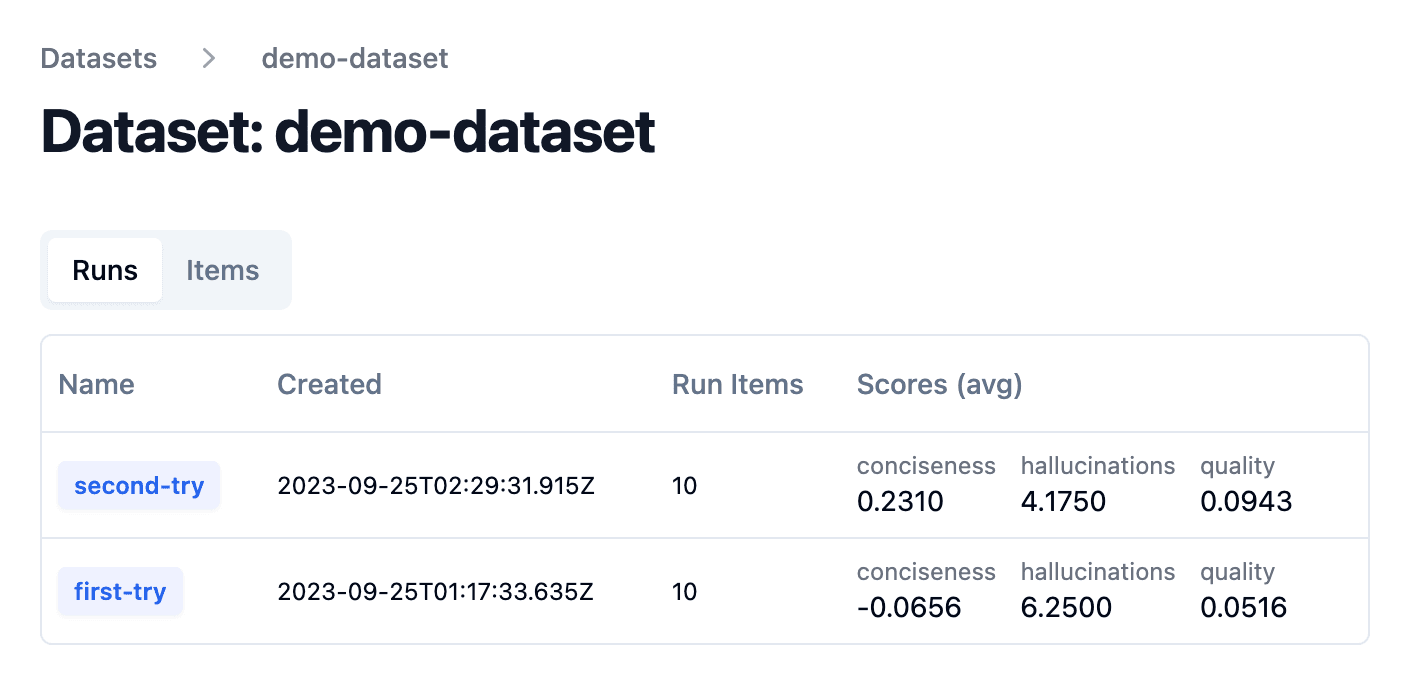
Run experiment on dataset
dataset = langfuse.get_dataset("<dataset_name>")
for item in dataset.items:
# execute application function and get Langfuse parent observation (span/generation/event)
# output also returned as it is used to evaluate the run
generation, output = my_llm_application.run(item.input)
# link the execution trace to the dataset item and give it a run_name
item.link(generation, "<run_name>")
# optionally, evaluate the output to compare different runs more easily
generation.score(
name="<example_eval>",
# any float value
value=my_eval_fn(
item.input,
output,
item.expected_output
)
)Datasets are currently in beta on Langfuse Cloud as the API might still slightly change. If you’d like to try it, let us know via the in-app chat.
→ Dataset docs → Python Cookbook
📊 In-app dashboards
Over the last weeks, analytics features were in public alpha on Langfuse Cloud. We’ve now shipped a new query engine as an underlying abstraction for the native in-app dashboards. This is a major step towards bringing all analytics features into the Langfuse core project and helps us move much faster on these.
Over the next days, you’ll see more and more dashboards popping up in the app. If there is a specific analysis you’d like to see, suggest it on Discord.
🔄 New integrations
The new integrations make it easier to get started with Langfuse. Thanks to the teams behind Langflow, Flowise and LiteLLM for building/collaborating on these integrations.
See integrations docs for details:
- Langflow: No-code LLM app builder in Python
- Flowise: No-code LLM app builder in JS
- LiteLLM: Python library to use any LLM model as drop in replacement of OpenAI API
🔎 Complex filters for all tables
You can now filter all tables in Langfuse by multiple columns.
🌐 Share traces via public link
Share traces with anyone via public links. The other person doesn’t need a Langfuse account to view the trace.
💾 Export generations (for fine-tuning)
In addition to the GET API, you can now directly export generations from the Langfuse UI. Supported formats: CSV, JSON, OpenAI-JSONL.
Use Langfuse to capture high-quality production examples (e.g. from a larger model) and export them for fine-tuning.

🚢 What’s Next?
There is more coming in October. Stay tuned! Based on the new query engine we’ll ship extensive dashboards over the next weeks. Anything you’d like to see? Join us on Discord and share your thoughts.
Subscribe to get monthly updates via email:
Follow along on Twitter (@Langfuse, @marcklingen)